How Did Sc Miss the Top 25 Again
How I scored in the top 9% of Kaggle's Titanic Machine Learning Challenge

For those aspiring to be Information Scientists or but those wanting to get their feet wet with automobile learning, Kaggle is a great site to try. Kaggle is a website that hosts a ton of machine learning competitions presented either by Kaggle itself or major companies such every bit Google, Intel, and Facebook. They accept a few beginner competitions for newbies, including their most popular one: The Titanic Machine Learning Challenge.
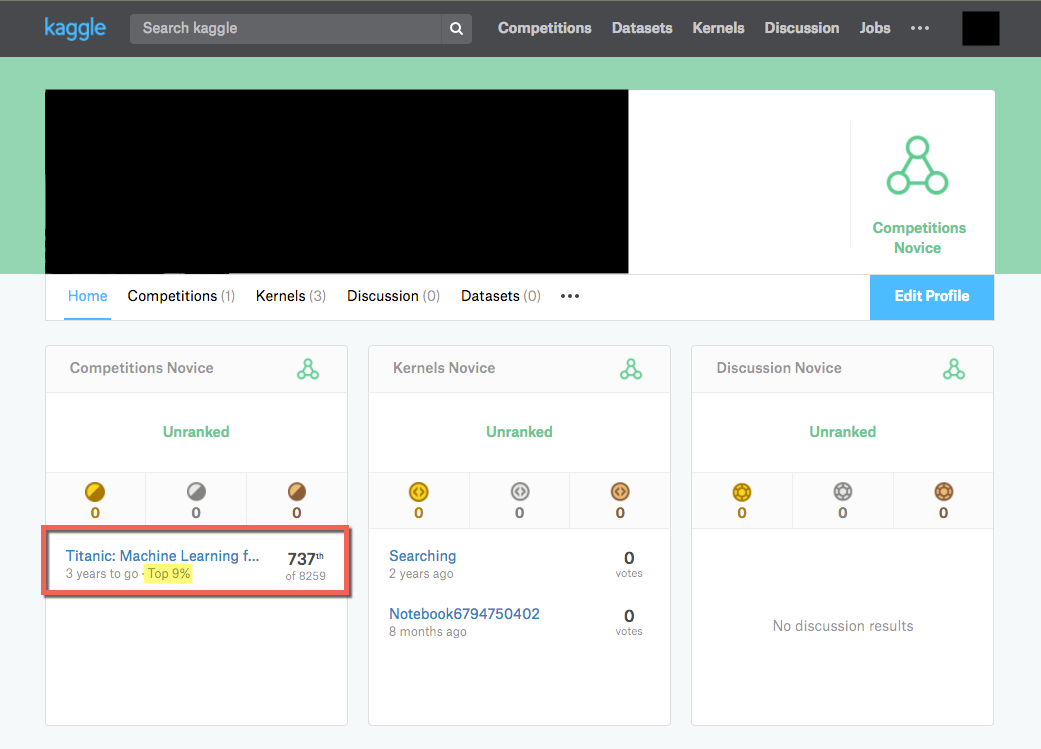
I only recently started "Kaggling" and I must say, the challenges tin can exist quite addicting as you try and improve your predictions and see your proper name soar up the leaderboards as your prediction scores meliorate. I decided to have a shot at the Titanic challenge and was able to crack the tiptop ix% with one of my submissions.
This mail will exist an abbreviated walk through of some of the data wrangling, feature engineering, and modeling I tried in order to achieve that score, just for the full code, feel complimentary to checkout my Jupyter Notebook on my GitHub business relationship.
Disclaimer: Yous will probably notice that some of the features I used are borrowed from other people that accept posted their results in other blogs. My work is an affiliation of what I have read on other blogs, a quick course I took on datacamp.com , and my own machine learning knowledge through my current Principal'south in Data Scientific discipline program.
The Titanic challenge of course is based on the infamous sinking of the behemoth passenger ship that sank in the middle of the Atlantic on Apr xv, 1912. A combination of icy cold waters, insufficient life boats for all passengers onboard, and other systematic failures led to one,502 out of the ii,224 passengers dying. The Kaggle claiming provides data on 891 passengers (the training data), including wether they survived or not and the goal is to employ that data to predict the fate of 418 passengers (the exam data) whose fate is unknown.
Here are the modules I used for this project:
# classifier models
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV # modules to handle information
import pandas equally pd
import numpy as np
I. Information Wrangling and Preprocessing
Kaggle provides a test and a train dataset. The preparation information provides a Survived column which shows a 1 if the passenger survived and a 0 if they did non. This is ultimately the characteristic we are trying to predict so the examination set will not have this column.
Because I'm lazy and don't similar doing things twice, I first loaded the data into a railroad train and test variable and then created a titanic variable where I appended the examination to the train so that I tin can create new features to both data sets at the aforementioned fourth dimension. I likewise created an index for each train and test so that I can separate them out later into their corresponding train and examination.
# load data
train = pd.read_csv('./Data/train.csv')
examination = pd.read_csv('./Data/examination.csv') # save PassengerId for final submission
passengerId = test.PassengerId# merge train and test
# create indexes to separate data later on
titanic = train.append(test, ignore_index=True)
train_idx = len(train)
test_idx = len(titanic) - len(test)
Let'southward quickly peek at the data and come across what information technology looks like:
# view head of data
titanic.head() 
With the full data in the titanic variable, we tin can employ the .info() method to get a description of the columns in the dataframe.
# become info on features
titanic.info() 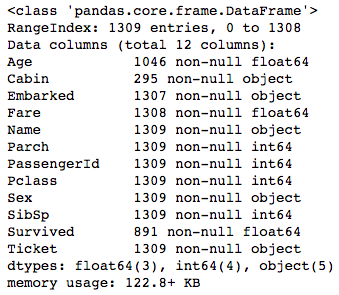
This shows us all the features (or columns) in the data frame along with the count of non-null values. Looking at the RangeIndex we see that there are 1309 total entries, just the Historic period, Cabin, Embarked, Fare, and Survived have less than that, suggesting that those columns have some aught, or NaN, values. This is a muddied dataset and nosotros either need to drop the rows with NaN values or fill in the gaps past leveraging the data in the dataset to gauge what those values could have been. We will choose the latter and attempt to judge those values and fill in the gaps rather than lose observations. However, one affair to notation is that the Survived feature will not require the states to fill in the gaps equally the count of 891 represents the labels from the train information. Remember that we are trying to predict the Survived column and then the examination set does not have this cavalcade at all.
Even though this is technically the "Data Wrangling" department, earlier we do any information wrangling and address whatever missing values, I first want to create a Championship feature which only extracts the honorific from the Proper name characteristic. But put, an honorific is the championship or rank of a given person such every bit "Mrs" or "Miss". The post-obit code takes a value like "Braund, Mr. Owen Harris" from the Name column and extracts "Mr":
# create a new characteristic to extract title names from the Proper name column
titanic['Title'] = titanic.Name.employ(lambda proper name: name.split(',')[1].split('.')[0].strip()) After viewing the unique Titles that were pulled, we run into that we have 18 different titles only nosotros will want to normalize these a chip and then that we can generalize a bit more. To practice this, we will create a dictionary that maps the 18 titles to 6 broader categories and so map that dictionary back to the Title feature.
# normalize the titles
normalized_titles = {
"Capt": "Officer",
"Col": "Officeholder",
"Major": "Officer",
"Jonkheer": "Royalty",
"Don": "Royalty",
"Sir" : "Royalty",
"Dr": "Officer",
"Rev": "Officer",
"the Countess":"Royalty",
"Dona": "Royalty",
"Mme": "Mrs",
"Mlle": "Miss",
"Ms": "Mrs",
"Mr" : "Mr",
"Mrs" : "Mrs",
"Miss" : "Miss",
"Main" : "Master",
"Lady" : "Royalty"
} # map the normalized titles to the current titles
titanic.Title = titanic.Championship.map(standardized_titles) # view value counts for the normalized titles
print(titanic.Championship.value_counts())
Printing the result gives us the following counts:

The reason I wanted to create the Title feature showtime was so that I could utilize information technology to estimate the missing ages but a little chip better. The next step is to estimate the missing Historic period values. To do this, we will group the dataset by Sex, Pclass (Passenger Course), and Title.
# group by Sex, Pclass, and Title
grouped = titanic.groupby(['Sex','Pclass', 'Championship']) # view the median Age by the grouped features
grouped.Age.median()
Which gives us:
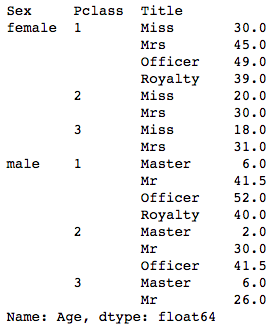
Instead of simply filling in the missing Historic period values with the mean or median age of the dataset, past grouping the data by a rider's sex, class, and championship, we can drill down a bit deeper and get a closer approximation of what a passenger's age might take been. Using the grouped.Age variable, we can fill up in the missing values for Historic period.
# employ the grouped median value on the Age NaN
titanic.Historic period = grouped.Age.apply(lambda x: x.fillna(10.median())) Next, we move onto the next features with missing values, Cabin, Embarked, and Fare. For these, we wont be doing anything too fancy. We will fill Cabin with "U" for unknown, Embarked nosotros volition make full with the most frequent point of embarkment, and since Fare but has 1 missing value we will simply make full it in with the median value of the dataset:
# fill up Motel NaN with U for unknown
titanic.Motel = titanic.Cabin.fillna('U') # find well-nigh frequent Embarked value and store in variable
most_embarked = titanic.Embarked.value_counts().index[0]# fill NaN with most_embarked value
# fill up NaN with median fare
titanic.Embarked = titanic.Embarked.fillna(most_embarked)
titanic.Fare = titanic.Fare.fillna(titanic.Fare.median())# view changes
titanic.info()
And at present we view the information with .info() again:
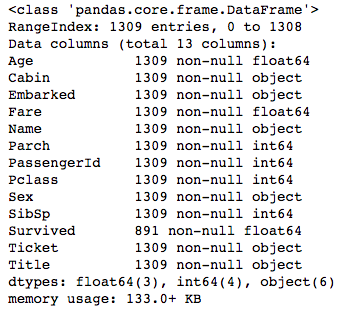
Everything looks good at present. As expected, Survived still has missing values just since nosotros are going to eventually be splitting the data back to railroad train and test, we can ignore that for now.
II. Feature Engineering
We volition apace create two more features before nosotros begin our modeling. The next feature of interest is family unit size per rider, since having a larger family may have fabricated it harder to secure a spot on a life gunkhole compared to an individual rider or a small family unit trying to get on a life boat. Nosotros can leverage the SibSp and Parch features to make up one's mind family size since these are a count of sibling/spouse and parent/children respectively per passenger.
# size of families (including the rider)
titanic['FamilySize'] = titanic.Parch + titanic.SibSp + 1 The final feature we will create volition leverage the Cabin characteristic and only extract the first letter of the cabin which determines the section where the room would have been. This is potentially relevant since it is possible that some cabins were closer to the life boats and thus those that were closer to them may have had a greater gamble at securing a spot.
# map offset letter of cabin to itself
titanic.Cabin = titanic.Cabin.map(lambda 10: x[0]) If you view the head of your information, it should look like this now:

The last step to perform before we can brainstorm our modeling is convert all our chiselled features to numbers, as our algorithms can but take an assortment of numbers as an input, not names or messages. Every bit you noticed from the previous screenshot, we have a few columns to convert. We use the pd.get_dummies() method from Pandas that converts categorical features into dummy variables.
# Convert the male person and female groups to integer form
titanic.Sex = titanic.Sex.map({"male": 0, "female":1}) # create dummy variables for categorical features
pclass_dummies = pd.get_dummies(titanic.Pclass, prefix="Pclass")
title_dummies = pd.get_dummies(titanic.Title, prefix="Title")
cabin_dummies = pd.get_dummies(titanic.Cabin, prefix="Cabin")
embarked_dummies = pd.get_dummies(titanic.Embarked, prefix="Embarked") # concatenate dummy columns with main dataset
titanic_dummies = pd.concat([titanic, pclass_dummies, title_dummies, cabin_dummies, embarked_dummies], axis=1)# drop chiselled fields
titanic_dummies.drop(['Pclass', 'Championship', 'Motel', 'Embarked', 'Proper noun', 'Ticket'], axis=1, inplace=True)titanic_dummies.head()
Viewing the head once again nosotros go:

Perfect! Our data is now in the format nosotros demand to perform some modeling. Let's separate it back into train and test data frames using the train_idx and test_idx we created in the commencement of the practise. We will also separate our preparation data into 10 for the predictor variables and y for our response variable which in this example is the Survived labels.
# create train and test data
train = titanic_dummies[ :train_idx]
test = titanic_dummies[test_idx: ]# convert Survived dorsum to int
# create X and y for data and target values
train.Survived = railroad train.Survived.astype(int)
X = railroad train.drib('Survived', centrality=1).values
y = train.Survived.values # create assortment for exam set up
X_test = test.drop('Survived', axis=1).values
3. Modeling
I tested both a logistic regression model, which is a binary classifier, and a random forrest classifier model which fits a number of conclusion tree classifiers on the data. I used GridSearchCV to pass in a range of parameters and have it return the best score and the associated parameters.
The logistic regression model returned a best score of ~82% while the random forrest model got a best score of ~84% which is the model I concluded up using for my predictions. As a upshot, I volition only cover the random forrest model in this section.
GridSearchCV needs the estimator argument which in this instance is the random forrest model and a param_grid which is a dictionary of parameters for the estimator. To forestall this postal service from being longer than information technology needs to be, I will let you lot look upward the documentation for the random forrest classifier to discover out what the parameters practice.
Beginning, I created my dictionary of parameters with different ranges:
# create param grid object
forrest_params = dict(
max_depth = [due north for n in range(ix, 14)],
min_samples_split = [north for n in range(iv, 11)],
min_samples_leaf = [n for n in range(2, 5)],
n_estimators = [n for n in range(10, 60, x)],
) Next, I instantiate the random forrest classifier:
# instantiate Random Forest model
forrest = RandomForestClassifier() Lastly, we build the GridSearchCV and fit the model:
# build and fit model
forest_cv = GridSearchCV(estimator=forrest, param_grid=forrest_params, cv=five) forest_cv.fit(X, y)
Once this finishes (and it will take quite a few minutes depending on your computer's speed) you can use the best_score_ and best_estimator_ methods to recall the best score and the parameters that led to that score:
print("Best score: {}".format(forest_cv.best_score_))
impress("Optimal params: {}".format(forest_cv.best_estimator_)) 
At present nosotros are gear up to predict and submit! Remember that nosotros saved the exam set under X_test, and so we tin simply practice the following:
# random forrest prediction on test set
forrest_pred = forest_cv.predict(X_test) forrest_pred returns a 418 10 1 assortment of predictions for the Survived values. In the very showtime step, I placed the PassengerId column from the original test information into its own variable that I named passengerId. For our final submission, all nosotros have to exercise is combine the passengerId with forrest_pred into a information frame and output to a csv. The post-obit code does this:
# dataframe with predictions
kaggle = pd.DataFrame({'PassengerId': passengerId, 'Survived': forrest_pred}) # save to csv
kaggle.to_csv('./Information/titanic_pred.csv', alphabetize=False)
This is what it looked similar when I submitted it:
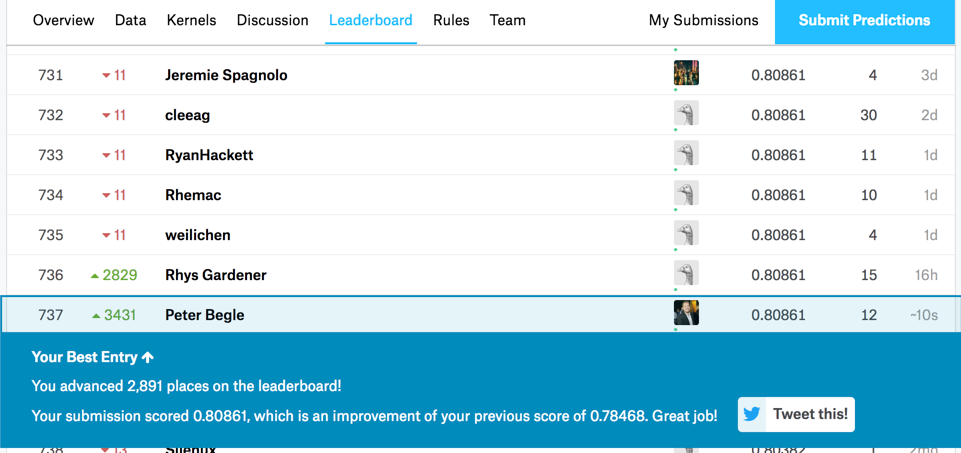
This got me a score of 0.80861 which was skilful enough for top 9% at the time of submission.
Hopefully that was informative for anyone who made it all the fashion to this point and I hope you can take from my submission and add your own ideas to endeavour and get an even higher score!
howardwitildrosen.blogspot.com
Source: https://medium.com/i-like-big-data-and-i-cannot-lie/how-i-scored-in-the-top-9-of-kaggles-titanic-machine-learning-challenge-243b5f45c8e9
{kind=link}
Post a Comment for "How Did Sc Miss the Top 25 Again"