kitti draw 3d box on image
Orientation Interpretation in Monocular 3D Object Detection
![]()
Monocular 3D object detection is the task to draw 3D oriented bounding box around objects in 2nd RGB image. This task has attracted lots of interest in the democratic driving industry due to the potential prospects of reduced cost and increased modular redundancy. The task of reasoning 3D with a unmarried second input is highly challenging, and estimation of vehicle orientation is ane of import footstep toward this of import task.

In monocular 3D object detectio north , i of import concept that keeps coming upward in literature is the difference between allocentric and egoistic orientation. I have recently explained the deviation to many of my colleagues and I recall it is a good fourth dimension to write a short blog post about this.
Note that this post focuses on the concept of 3D orientation in democratic driving. If you lot want to know the state-of-the-art ways for orientation regression, delight read my previous post on Multi-modal Target Regression, in particular for orientation regression.
Egoistic vs Allocentric
The concepts of egocentric and allocentric came from the field of human being spatial noesis. However, these concepts in the context of perception in autonomous driving are quite specific: egocentric orientation means orientation relative to photographic camera, and allocentric orientation is orientation relative to object (i.e., vehicles other than the ego vehicle).
Egocentric orientation is sometimes referred to as global orientation (or rotation around Y-centrality in KITTI, every bit mentioned below) of vehicles, as the reference frame is with respect to the photographic camera coordinate system of the ego vehicle and does not modify when the object of interest moves from one vehicle to some other. Allocentric orientation is sometimes referred to as local orientation or observation angle, as the reference frame changes with the object of interest. For each of the object, there is one allocentric coordinate organisation, and one axis in the allocentric coordinate organization aligns with the ray emitting from the camera to the object.
To illustrate this simple idea, the paper FQNet (Deep Fitting Degree Scoring Network for Monocular 3D Object Detection, CVPR 2019) has a corking illustration.
In (a), the global orientations of the auto are all facing the correct, but the local orientation and appearance will change when the motorcar moves from the left to the correct. In (b), the global orientations of the car differ, just both the local orientation in the camera coordinates and the appearance remain unchanged.
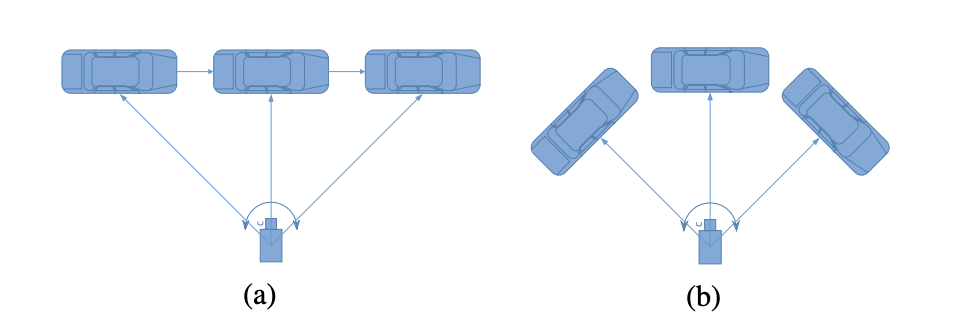
It is obvious to come across that the appearance of an object in the monocular paradigm only depends on the local orientation, and we can only regress the local orientation of the car based on the appearance. Another slap-up analogy is from the Deep3DBox newspaper (3D Bounding Box Estimation Using Deep Learning and Geometry, CVPR 2017).

The car in the cropped images rotates while car direction in 3D earth is constant — following the straight lane lines. From just the epitome patches on the left, information technology is most impossible to tell the global orientation of the car. The context of the car in the entire image is critical to infer the global orientation. On the other mitt, local orientation can be fully recovered from the prototype patch alone.
Notation that following KITTI'south convention of assuming null roll and naught pitch, the orientation is reduced to simply yaw. Thus the above two orientations are referred to as global yaw and local yaw likewise.
Converting local to global yaw
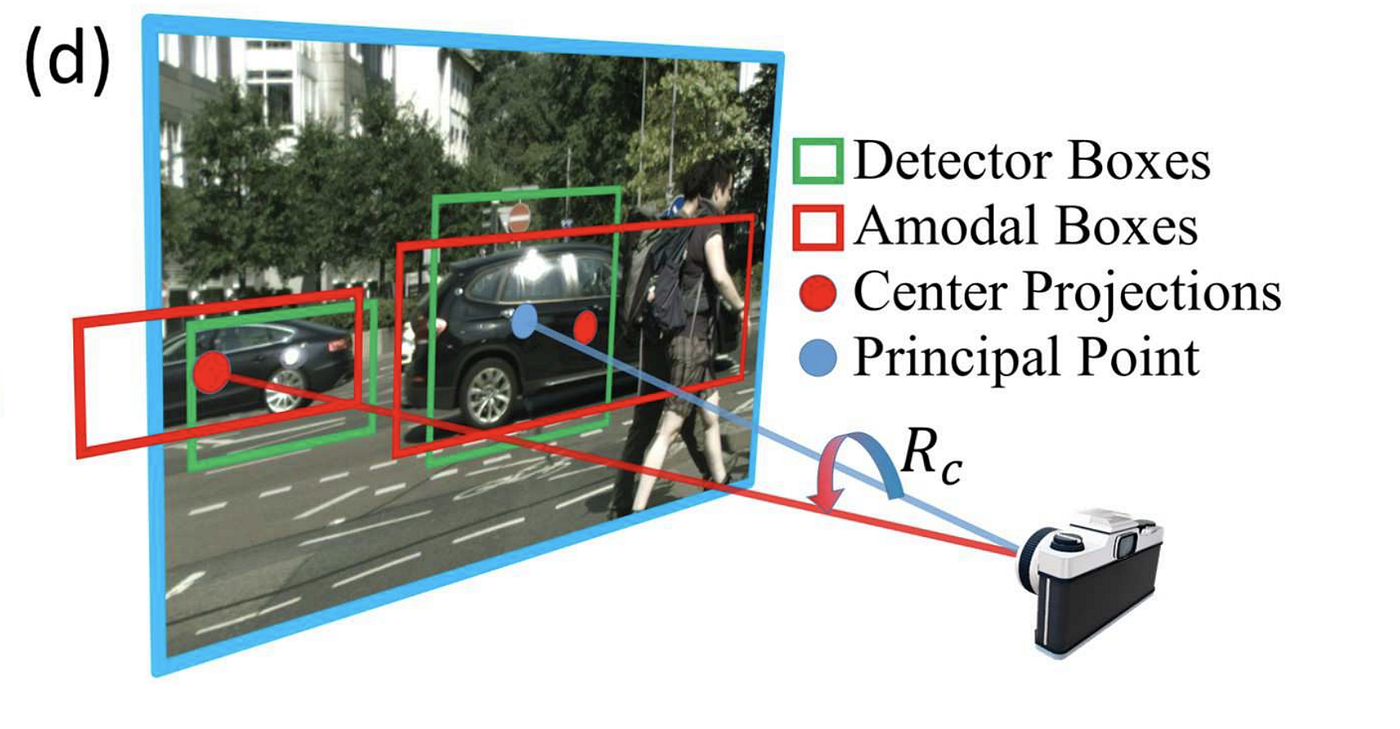
To compute the global yaw using local yaw, we need to know the ray direction between the camera and the object, which can be calculated using the location of the object in the 2nd paradigm. The conversion is a simple add-on, as explained in the diagram below.

The angle for the ray direction can be obtained using a keypoint from the bounding box position and the camera intrinsics (chief signal and focal length) of the camera. Annotation that there are different choices for picking the keypoint of a 2D bounding box. Some popular choices are:
- heart of detector boxes (may be truncated)
- center of amodal boxes (with guessed extension for occluded or truncated object)
- project of 3D bounding box on the image (can exist obtained from lidar 3D bounding box ground truth)
- bottom center of 2D bounding box (which is often assumed to be on the ground)
The bottom line is, unless the vehicle is really closeby or severely truncated or occluded, the higher up methods will yield angle estimation of about one to 2 degrees autonomously.
What does the KITTI say?
KITTI dataset'due south 2nd object detection ground truth provides ii angles for each bounding box:
- alpha: Observation angle of object, ranging [-pi..pi]
- rotation_y: Rotation ry around Y-axis in photographic camera coordinates [-pi..pi]
The above two angles stand for to the local (allocentric) yaw and global (egocentric) yaw, respectively. These values seem to come from 3D bounding box ground truth based on lidar data. This makes it easy to perform angle estimation on the 2nd images.
KITTI has one official metric on orientation estimation: Average Orientation Similarity (AOS), a value between 0 and i, and 1 represents perfect prediction. I will not go to details about the metric here, but it is quite similar to the thought of Average Precision and the details can be found in the original KITTI paper.
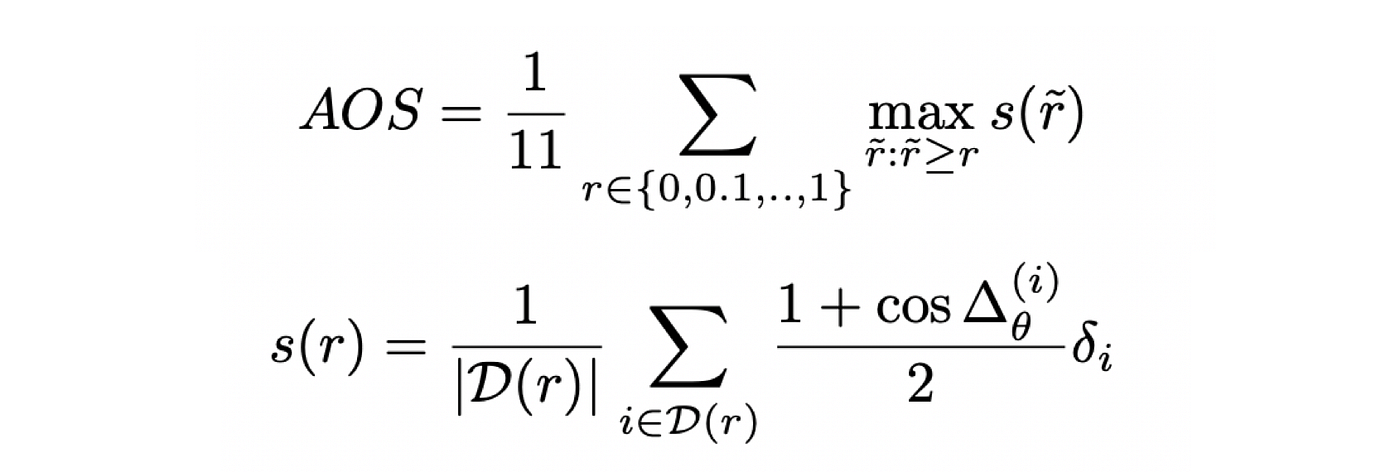
At that place is another metric in literature popularized past 3D RCNN, Average Angular Fault (AAE), divers below.
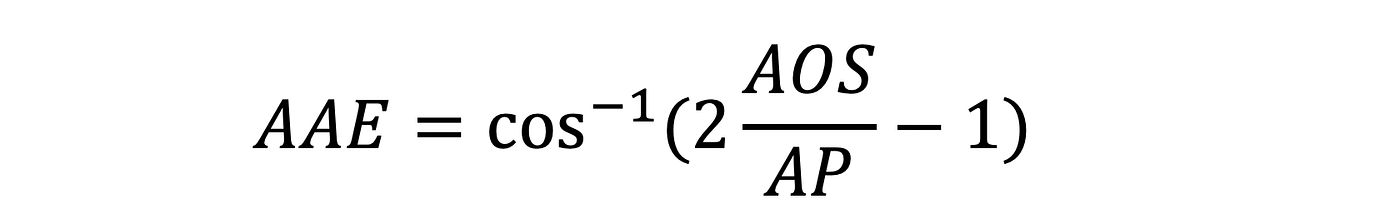
Takeaways
- Information technology is possible to estimate the local (allocentric) orientation (yaw) from a local paradigm patch.
- It is impossible to estimate the global (egoistic) orientation (yaw) from a local image patch.
- With camera intrinsic (principal point, focal length) and global information of the image patch, it is possible to convert the local orientation to global orientation.
- The regression of viewpoint orientation is one of the hardest regression issues in deep learning. Refer to my previous post on Multi-modal Target Regression.
I will write a review of monocular 3D object detection soon. Stay tuned!
howardwitildrosen.blogspot.com
Source: https://towardsdatascience.com/orientation-estimation-in-monocular-3d-object-detection-f850ace91411
{kind=link}
Post a Comment for "kitti draw 3d box on image"